Informatics Platforms and Analysis
Informatics Platforms and Analysis
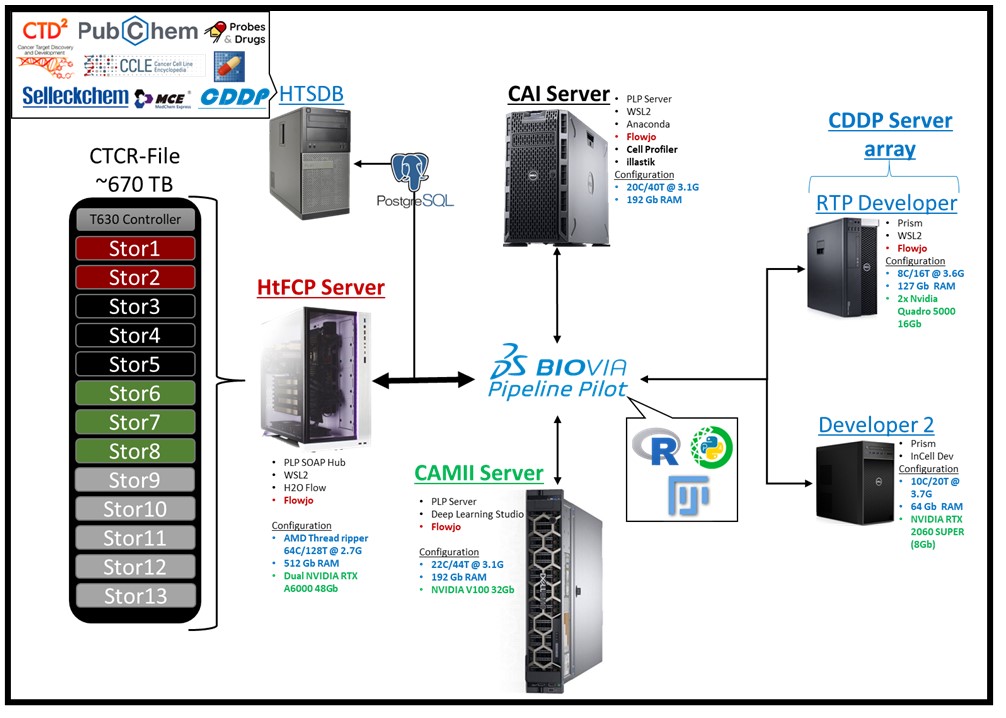
The joint data science program has a self-maintained computational cluster capable of processing and storing the large volumes of data produced by the Combinatorial Drug Discovery Program (CDDP), the Center for Advanced Imaging (CAI), Center for Advanced Microscopy and Image Informatics (CAMII), High-throughput Flow Cytometry Program (HtFCP), and the Microphysiological Lead Optimization and Toxicity screening facility (MLOTS) housed at the Texas A&M Institute of Biosciences and Technology. Central to this computational infrastructure is Pipeline Pilot Software (BIOVIA), which provides shared access of CPUs, GPUs, and RAM across decentralized workstations in addition to providing a wide array of software development and data management tools. In total this cluster contains over a terabyte of RAM, 248 logical processors, and 3 high-capacity GPU clusters. The joint data science program also maintains an actively expanding database containing a wide array of pharmacologic susceptibility data from 100s of unique cell line models and cell culture systems, harmonized chemical annotation information for multiple databased, raw annotated images from multiple research programs, and a large code base from applications ranging from basic statistics to advanced deep learning. Collectively, these resources server as a proprietary platform to rapidly develop technologies and uniquely contextualize information being generated by our core facilities.
Statistical services
- Rigor and reproducibility analysis
- Assay design optimization
- Data normalization and integration
- Exploratory data analysis
- Development of Machine learning/Deep Learning models
Image analysis services
- Development of custom image analysis pipelines
- Upscaling established protocols for HTS applications
- Established protocols for 2D monolayers, organoids, spheroids, and time lapse data analysis
Bio- and Chemi-informatics support
- Chemical fingerprinting
- Quantitative structure activity relationship (QSAR)
- Pharmaco-genomics (PGx)/Bio-marker discovery
- Chemical annotation embedding
Key software and programming languages
- Pipeline Pilot from Biovia
- R programing language
- Python programing language
- Tensorflow/Keras and pytorch
- Prism from Graphpad
- IN Cell Developer from GE Life Sciences
- MetaXpress from Molecular Devices
- ImageJ from NIHs
- CellProfiler from the Broad Institute
- FlowJo from BD
- Microsoft 365
- Windows subsystem Linux version 2 (WSL2, Ubuntu 20.04)
- Adobe Creative Cloud
Key Computational infrastructure
- Dell T630, 20C/40T @3.1 GHz, 192 Gb RAM
- Dell ,10C/20T @3.7GHz, 64 Gb RAM, NVIDA RTX 2060 Super 8Gb
- Dell 7920, 8C/16T @3.6 GHz, 127 GB RAM, 2x NVIDIA Quadro 5000 16Gb
- Dell 740xd, 22C/44T @3.1 GHz, 192 GB RAM, NVIDIA V100 32Gb
- Lambda Vector, 64C/128C @2.7 GHz, 512 Gb RAM, 2x NVIDIA RTX A6000 48Gb
- Redundant Dell T640 with ME4084 PowerVault storage arrays